Use Machine Learning to predict Sports results (5 steps)
Use scikit-learn's classifier models to predict the results of a cricket match in the IPL tournament based on data from 2008 to 2020



In this blog, we are going to apply machine learning to statistical data to predict the result of a cricket match between 2 teams.
To make these predictions, we will use results for IPL matches from 2008 to 2010.
Find the predictions vs results table at the bottom of this page for the ongoing IPL 2021.
Github project - github.com/vandanaa-sharma/ipl_predictions
Python libraries used -
Steps -
- Import data
- Identify the problem
- Prepare data
- Create a model
- Measure accuracy
- And finally, make predictions!
1. Import data 💾
For this example, I've downloaded the data for all IPL matches between 2008-2020 from kaggle.com
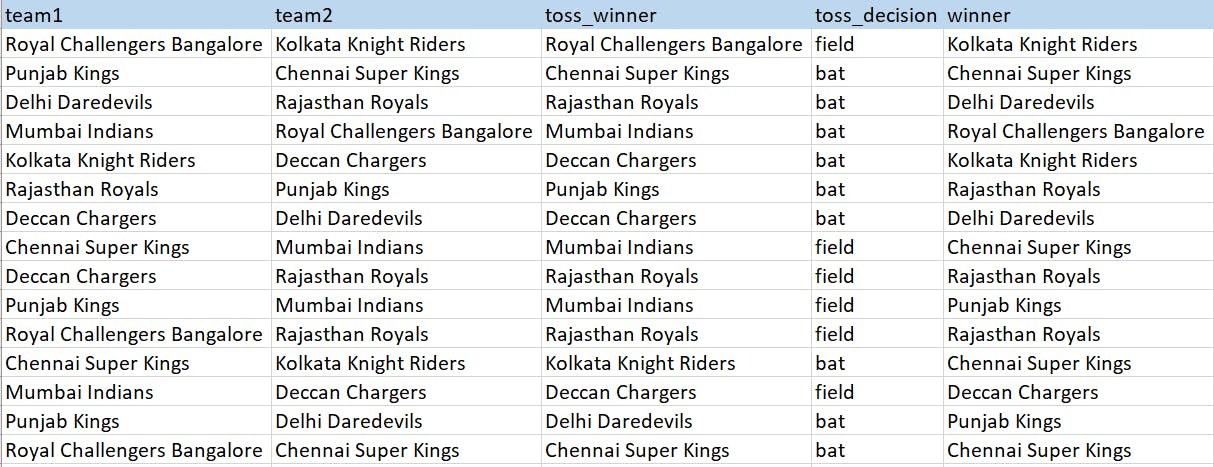
To import this data into the program, we'll be using pandas
import pandas as pd
data = pd.read_csv(r'data\IPL Matches 2008-2020.csv')
df = pd.DataFrame(data, columns= ['team1', 'team2', 'toss_winner','toss_decision', 'winner'])
You can inspect this imported data using dataframe functions as follows -
print(df.shape)
----------------------------------
Output -
(816, 5)
-------------------------------------------------------------------------------
print(df.describe())
----------------------------------
Output -
team1 team2 toss_winner toss_decision winner
count 816 816 816 816 812
unique 15 15 15 2 15
top Royal Challengers Bangalore Mumbai Indians Mumbai Indians field Mumbai Indians
freq 108 106 106 496 120
-------------------------------------------------------------------------------
Note that in this case we are only selecting the columns - team1, team2, toss_decision and toss_winner from this downloaded data to predict the winner.
The data has 816 rows (816 match results) for 15 teams, with 5 columns. And we have values present in all rows (no null values) as seen in the above description.
2. Identify the problem
Machine learning solutions are broadly classified as follows -
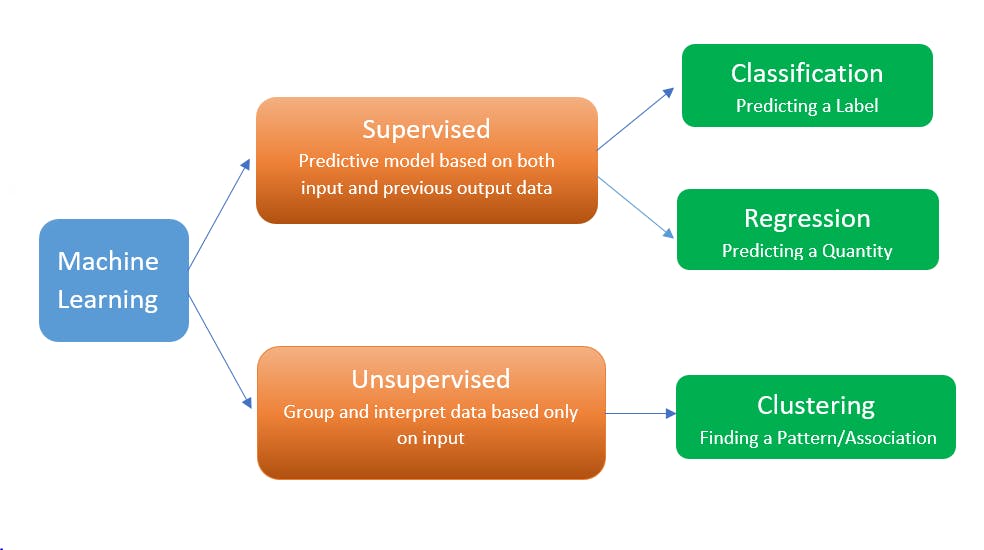
There are Semi-Supervised and Reinforcement categories in addition that you can look into.
So now, where does our problem fit?
We are trying to predict a winner based on who won historically, for the given values (team1, team2, toss_winner and toss_decision).
This problem comes under Classification.
3. Prepare Data 📚
1. Encode dataframe
The models used for classification work on numeric data. Since the data we have for classification (prediction) is string values, we are going to encode this data using LabelEncoder.
<!---Set 'chained_assignment' warnings generated by panda for copying dataframe to None --->
pd.options.mode.chained_assignment = None
<!---Create a copy for encoding dataframe into numbers--->
df1 = df.copy()
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df1['toss_winner'] = le.fit_transform(df1['toss_winner'])
df1['winner'] = le.fit_transform(df1['winner'])
df1['team1'] = le.fit_transform(df1['team1'])
df1['team2'] = le.fit_transform(df1['team2'])
Note - You can only use LabelEncoder for columns that have same set of values. All the above columns have same values i.e. the name of one of the teams, hence it is safe to encode them using LabelEncoder.
Now, the toss_decision column has different values from the above columns -- bat/field. So we are going to use our own encoding for this.
df1.loc[(df1.toss_decision =='bat'), 'toss_decision'] = 101
df1.loc[(df1.toss_decision =='field'), 'toss_decision'] = 100
2. Split the data 📑✂️
We need to split the data into -
- What to use for prediction --> X (team1, team1, toss_winner and toss_decision)
- What to predict --> Y (winner)
Do this as follows -
X = df1.drop(columns=['winner'])
Y = df1['winner']
Now, we are going to further split this data as follows -
- 80% of the data for training the model
- 20% for testing the accuracy of the model
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2)
4. Create a model 🧠
To create a model we are going to use the classification algorithms available in scikit-learn library (sklearn)
There are various Classification algorithms you can choose from - DecisionTreeClassfier, RandomForestClassifier, LinearRegression, GaussianNB, etc. You can try all of them and use the one with the highest accuracy.
For this example, we'll be using DecisionTreeClassifier. I've also included RandomForestClassifier results on the github link.
It's as simple as this -
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(X_train, Y_train)
5. Measure accuracy 📏
We will now measure the accuracy of the above model against the 20% data we kept aside for testing.
dt_accuracy = dt.score(X_test, Y_test)*100
print('Model accuracy:', dt_accuracy)
--------------------------------------------------------------
Output -
Model accuracy: 79.26829268292683
Wow! Not bad at all!! 👏
You are now ready to
Make predictions 🔮
We are going to fetch the ongoing matches from [here ],(github.com/vandanaa-sharma/ipl_predictions/..) and try to predict the winning team.
Ongoing IPL matches -
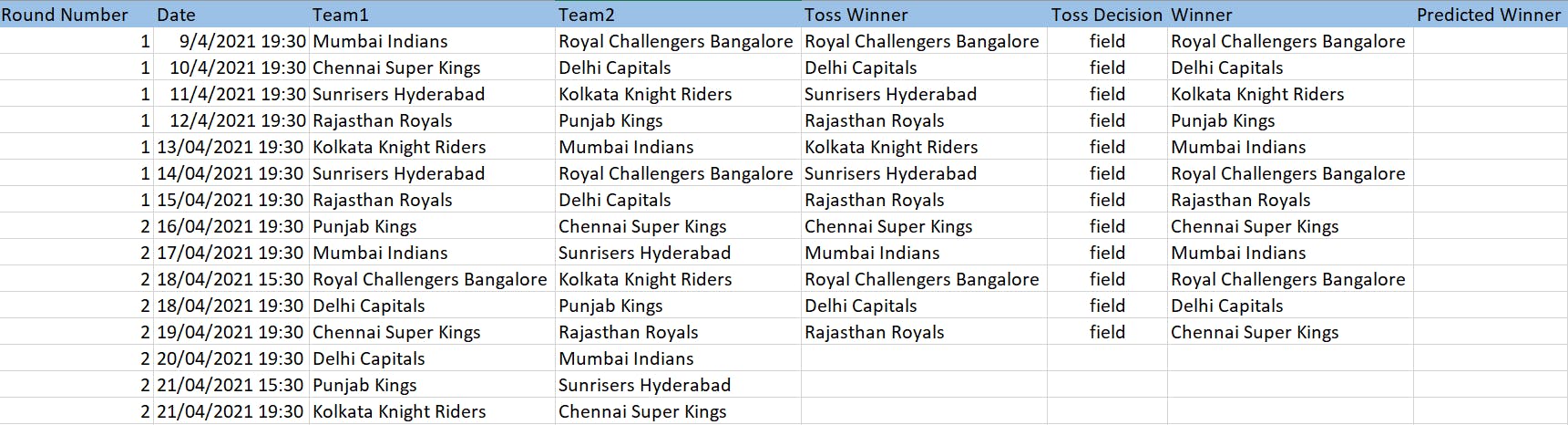
Prepare the test data -
We will import the data to predict for into a dataframe, like we did for previous dataset. Then iterate over each row and predict the winning team.
At the end, we will be storing the predicted results in a new csv file.
matches = pd.read_csv(r'data\ipl-2021-matches.csv')
df_matches = pd.DataFrame(matches, columns= ['Team1', 'Team2', 'Toss Winner','Toss Decision', 'Winner'])
result = [None]*df_matches.shape[0]
for index, row in df_matches.iterrows():
t1 = str(row['Team1'])
t2 = str(row['Team2'])
toss_winner = row['Toss Winner']
if type(toss_winner) is float:
break
toss_decision = str(row['Toss Decision'])
if(toss_decision == 'bat'):
toss_decision = int(101)
else:
toss_decision = int(100)
test_data = le.transform([t1, t2, toss_winner])
test_data = np.append(test_data, [toss_decision])
Now, the test data is ready for each row, continue the above loop to make prediction for current row -
result[index] = le.inverse_transform(dt.predict([test_data]))[0]
Here, we are using le.inverse_transform to tranform the encoded value back to the team name and storing the result at the current row index.
Finally, add this outside the loop to save the results at the end -
df_matches['Predicted Winner'] = result
df_matches.to_csv("Results.csv")
Results -
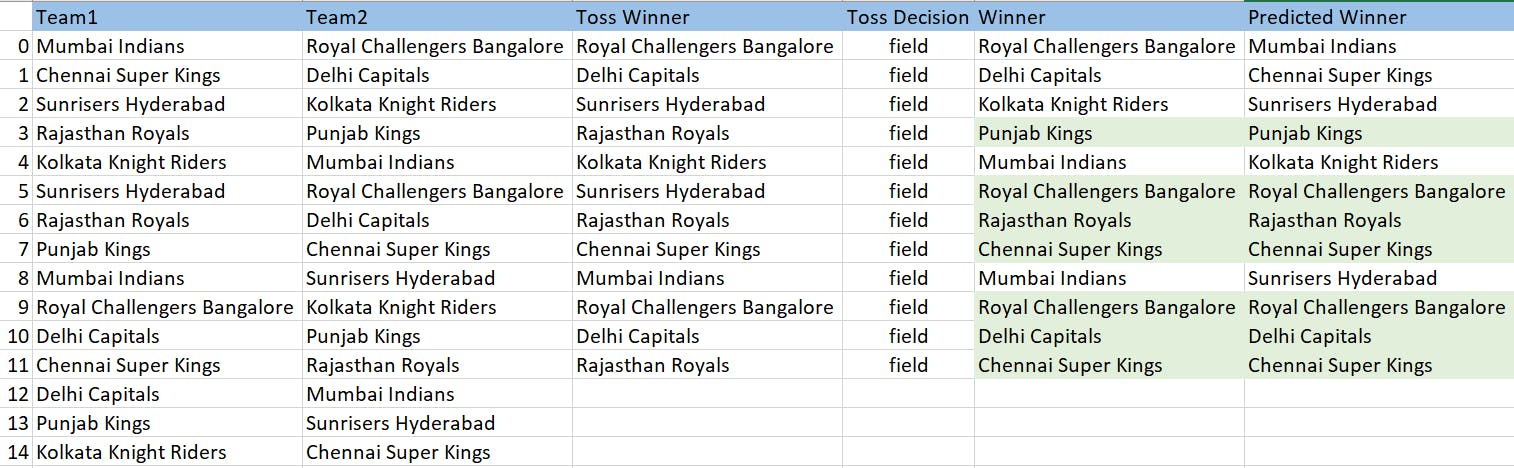 Checkout all this put together here.
Checkout all this put together here.
You can check the predictions and accuracy for this data using RandomForestClassifier in the same manner -
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X, Y)
print('RF accuracy: ', str(round(rf.score(X_test, Y_test)*100, 2)) + "%")
---------------------------------------------
Output -
RF accuracy: 76.83%
Bonus Tip
You can also store the model you created above as a file, import and use it directly for further prediction -
import joblib
joblib.dump(dt, 'ipl_winner_prediction.joblib')
dt_loaded_from_file = joblib.load('ipl_winner_prediction.joblib')
print(le.inverse_transform(dt_loaded_from_file.predict([test_data]))[0])
Thank you and have fun predicting the future! :)